

UPD. полностью отказался от строк, остальное актуально
Сегодня я хотел бы рассказать о работе с секторами в JARG.
Как и во многих других проектах, карта в JARG разделена на сектора, был выбран размер 25, привычные степени двойки плохо подходили - 16 слишком мало, 32 - слишком много.
Изначально Система хранения секторов выглядела очень просто: словарь активных секторов, которые выводятся непосредственно, и словарь всех секторов. При запросе любого блока или сектора поиск производился сначала в списке активных, а затем в списке всех, если сектор не находился, то он генерировался.
Изначально Система хранения секторов выглядела очень просто: словарь активных секторов, которые выводятся непосредственно, и словарь всех секторов. При запросе любого блока или сектора поиск производился сначала в списке активных, а затем в списке всех, если сектор не находился, то он генерировался.
Такая система была слабой во всех отношениях: нет абстракции доступа, невозможна фоновая генерация, неактивные сектора занимают огромный объем памяти (примерно по 70KiB на сектор из за большого количества списков и избыточной информации, присущей C#)
Было принято решение переделать систему.
Было принято решение переделать систему.
Первым улучшением стало абстрагирование класса, который занимается генерацией и передачей секторов классу игры - LevelWorker, запускает фоновый поток обработки всех запросов, а также занимающийся фоновой генерацией карты.
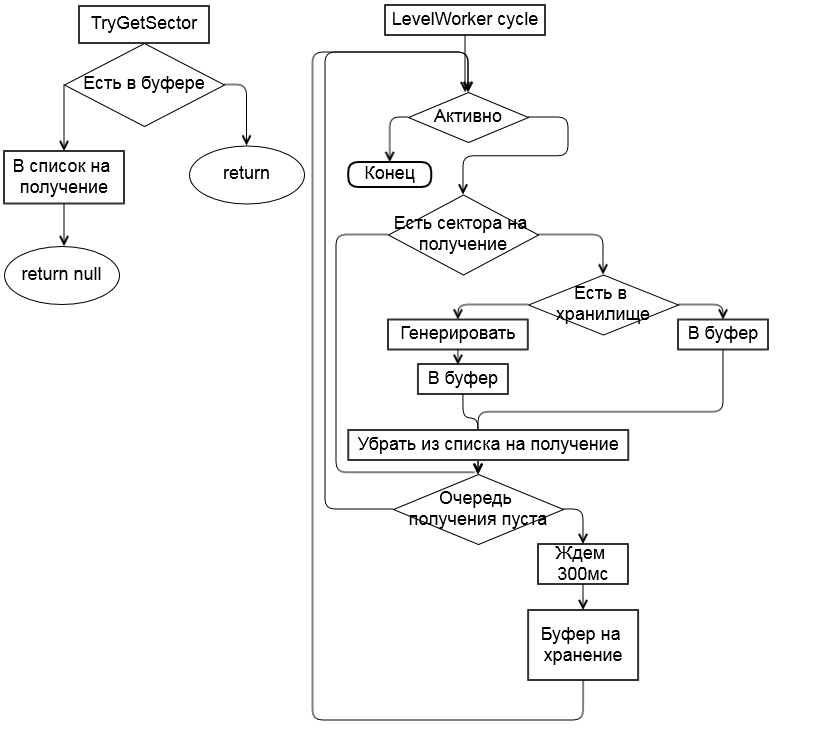
Вместо хранения секторов в виде экземпляров класса MapSector было выбрано хранение в сериализованном, сжатом виде. Сначала для каждого списка (блоков, полов, юнитов) формируется словарь, чтобы обозначать длинные идентификаторы одной цифрой, затем они сжимаются при помощи RLE (крайне успешно). В результате затраты на хранение сектора снизились с 70KiB, в среднем, до 800 B, а также полностью отпала необходимость подготовки секторов к сохранению на диск.
Сектора, которые запрашиваются игрой, создаются в виде экземпляра класса MapSector, из сериализованного представления, при возвращении их обратно на хранение, экземпляр сериализуется и разрушается..
К слову, адресация происходит по hash пары координат {x, y}, так что сложность поиска в любом из списков O(1)
Так же выделение абстракции позволило легко перенести LevelWorker на сервер без каких-либо серьезных изменений.
О генерации карты я расскажу в одной из следующих заметок.
И вообще. Преждевременная оптимизация корень всех зол
Ред. Pray_AD
P.P.S. Также стоить добавить, что все Id -- это интернированные, во время загрузки базы блоков, строки.